VideoUnderstanding
Multi-modal AI
Tech
TrustAndSafety
Scaling Trustworthy Video Safety with NVIDIA Nemotron 3 Nano Omni
2026. 4. 27.

PYLER AI Team
Video content moderation is one of the more challenging problems in modern ML. Unlike text or a still image, a video unfolds over time — and a clip that is perfectly benign for most of its duration can turn harmful for a few seconds in the middle. A safety system that only understands video at the “whole clip” level will either over-flag, under-flag, or miss the relevant moment entirely.
At PYLER, we've been building a video safety stack on top of open multimodal foundation models, and one question we kept coming back to was: which model actually holds up when you push it toward fine-grained, temporally grounded safety classification? We benchmarked the leading open-source candidates — Qwen2.5VL, Qwen3VL, Qwen2.5Omni, NVIDIA Nemotron-Nano-12B-v2VL, and NVIDIA Nemotron 3 Nano-Omni — and found that NVIDIA Nemotron 3 Nano-Omni is the strongest performer, both at the whole-video level and after decomposing the video into fine-grained temporal chunks.
Hereʼs how we got there.
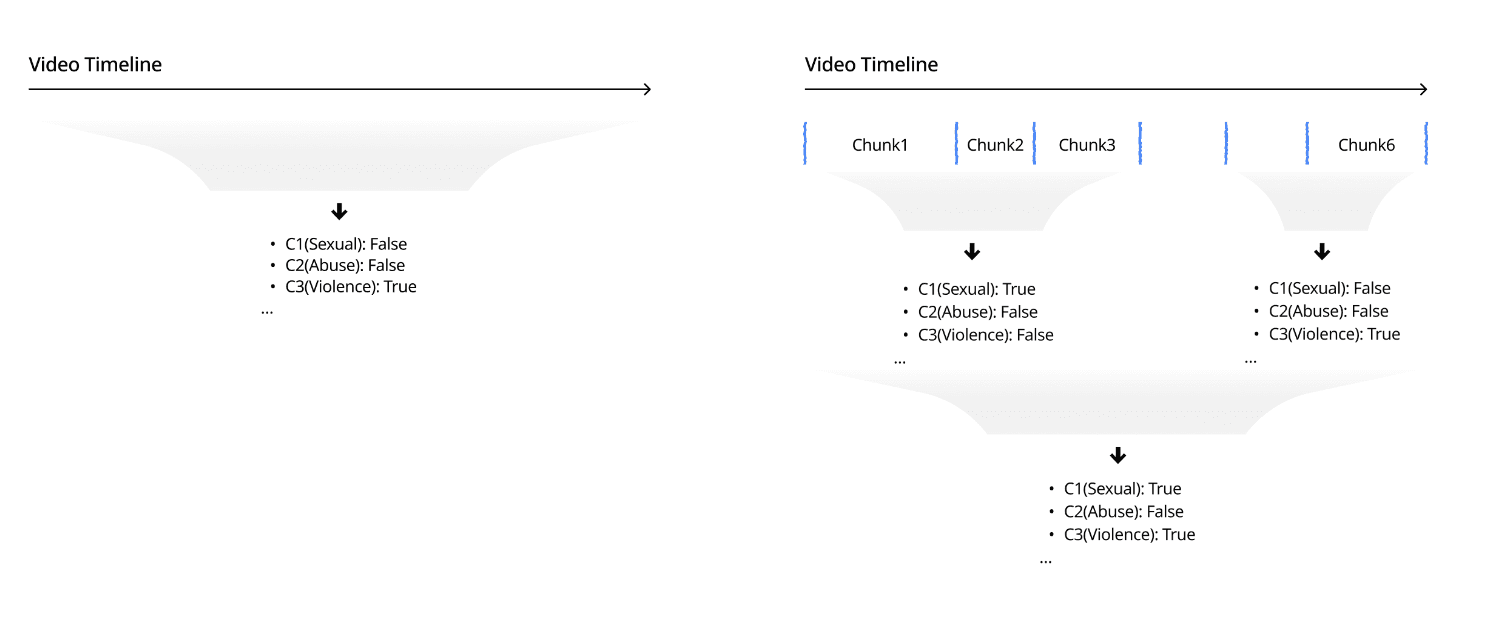
Why video safety needs two lenses
When classifying a video for safety, you generally have two options:
Whole-video classification. Feed the entire clip to the model and ask for a single safety verdict — a description, a set of policy labels, and a short rationale. Simple, fast, coarse.
Fine-grained, chunk-level classification. Split the video into temporal chunks, classify each chunk, and stitch the results back into a timeline. More expensive, but it tells you where the problem is — which is exactly what downstream systems (human review, timestamp redaction, parental warnings, ad placement) actually need.
Both lenses matter, and a model that is good at one but weak at the other is only half a product. So every model in our benchmark is evaluated under both modes.
Dataset: SafeWatch
For training and evaluation we build on SafeWatch ICLR 2025, a large-scale safety-policy-following video guardrail benchmark. It provides:
Training set: 8,152 videos, about 25,641 temporal chunks
Test set: 1,200 videos with video-level descriptions and labels
SafeWatch covers six policy categories — sexual content, harassment & bullying, threats / violence / harm, false & deceptive information, illegal / regulated activities, and hateful content & extremism — which maps cleanly onto most real-world moderation policies.
Evaluation: three benchmarks
To avoid over-fitting to any single slice of the problem, we built three evaluation
benchmarks covering different angles:
SafeWatch — Eval split. We split SafeWatchʼs training data into train and eval, using TransNet to recover temporal boundaries. This gives us clean chunk-level ground truth for in-distribution evaluation.
SafeWatch — Test split. Because the official test set only ships with video-level descriptions, we used NVIDIAʼs AI Blueprint VSS to pseudo-label chunk-level explanations and classifications — giving us a consistent target to measure fine-grained performance against.
VideoMME SafeWatch (Synthetic). To stress-test longer clips, we took normal videos from VideoMME and injected harmful segments into the middle. The model has to correctly temporally ground the injected portion — a direct test of localization quality on out-of-distribution content.

Metrics: accuracy and localization
We use two complementary metrics:
F1. Computed across all evaluation records, regardless of whether temporal matching succeeds. This captures raw classification accuracy — “did the model get the right category?”
tIoU (temporal IoU). Computed only on matched GT–prediction interval pairs. This isolates the quality of the temporal grounding itself — “did it localize the right moment?”
A strong video-safety model has to win on both. A model that labels correctly but localizes poorly wonʼt support real moderation workflows; a model that localizes well but mislabels sends the wrong signal downstream.
Inference pipeline: one backbone, two modes
The serving setup is the same regardless of which model we benchmark. We use vLLM for high-throughput inference and expose two modes:
Video-level inference. The model consumes the whole clip and emits a single (description, guardrail labels, explanation) output.
Chunk-level inference. The model consumes each temporal chunk and emits its own (description, guardrail labels, explanation) per chunk, which we stitch into a fine-grained safety timeline.
This gives us a clean, apples-to-apples comparison across models — same serving stack, same prompts, same output schema.
Results: NVIDIA Nemotron 3 Nano-Omni wins both modes
We evaluated five open-source multimodal models out of the box, on all three benchmarks, under both inference modes.
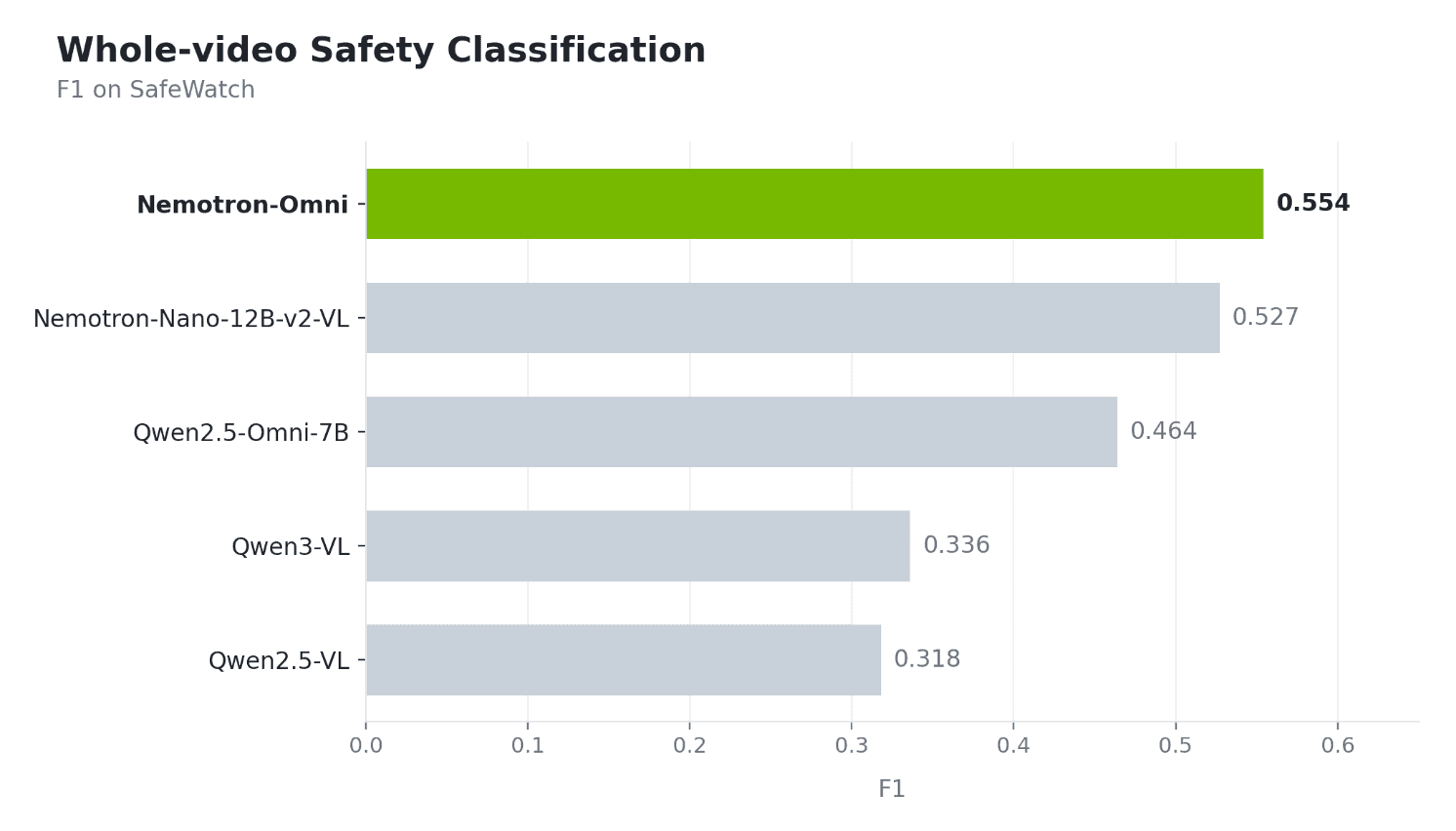
Whole-video classification (F1)
Fine-grained, chunk-level classification
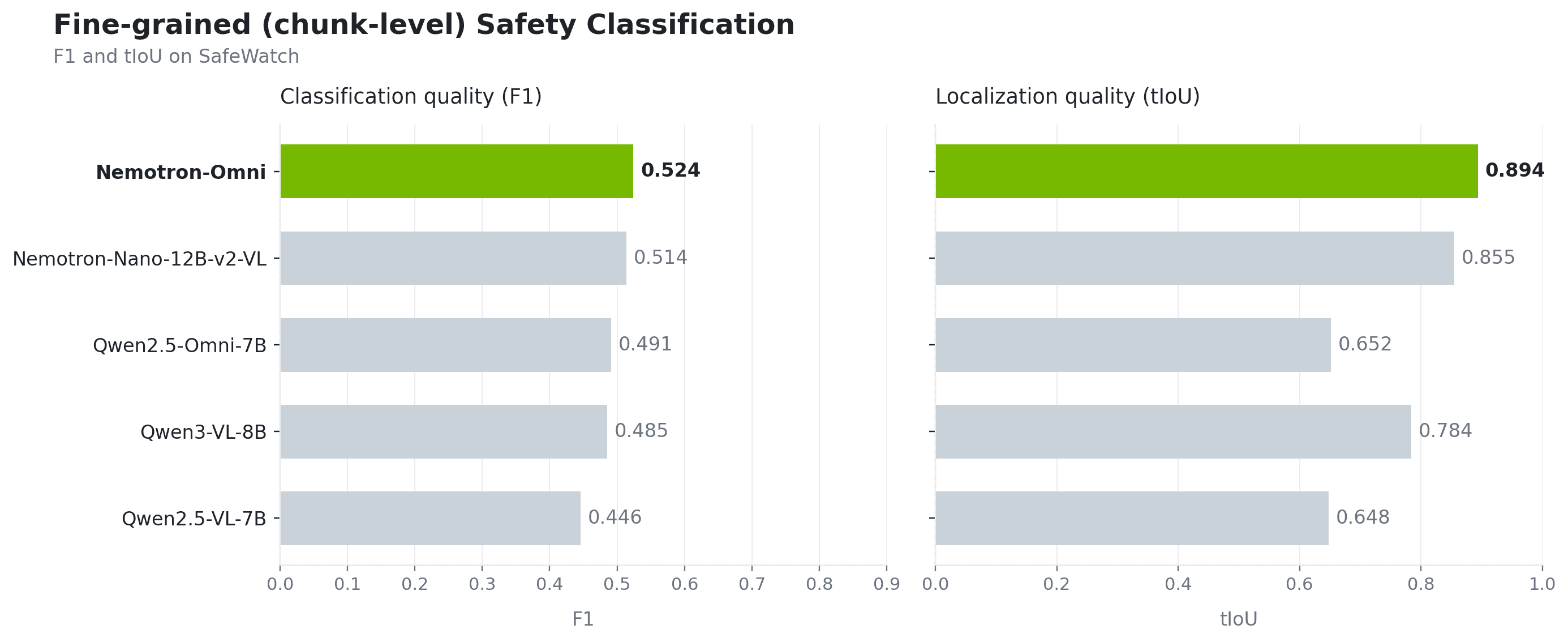
NVIDIA Nemotron 3 Nano-Omni is the strongest performer across the board. It takes the top spot on whole-video F1, the top spot on fine-grained F1 when we switch to chunk-level inference, and the best tIoU — which means it isnʼt just labeling the right category, itʼs also localizing when the harmful content happens.
Why NVIDIA Nemotron 3 Nano-Omni pulls ahead
A few observations from the evaluation:
Tested from two angles — whole-video and chunk-level. We ran every model under both inference modes. NVIDIA Nemotron 3 Nano-Omni is the only backbone that holds the top spot in both, showing it handles global reasoning as well as fine-grained per-chunk reasoning.
Balanced performance across categories. F1 rewards consistency across all six SafeWatch categories, not just the common ones. NVIDIA Nemotron 3 Nano-Omni holds up on the harder, underrepresented categories (deceptive information, hateful content) where smaller multimodal models tend to degrade.
Evaluated across three complementary benchmarks. Our evaluation surface spans in-distribution SafeWatch eval), pseudo-labeled test SafeWatch test), and an out-of-distribution stress test where harmful segments are injected into normal VideoMME clips. The top-line numbers shown above summarize the aggregate picture.
Takeaways
If you're building a video safety stack today, the choice of backbone matters a lot — and it matters more as you push toward fine-grained, temporally grounded classification. Our benchmark shows NVIDIA Nemotron 3 Nano-Omni to be the strongest open backbone for this setting, winning both at the whole-video level and after fine-grained decomposition.
We're continuing to push on post-training for even sharper temporal localization — but even before any fine-tuning, NVIDIA Nemotron 3 Nano-Omni already gives us the right foundation to build on.