Tech
Preference Optimization
Learning Where It Matters: Geometric Anchoring for Robust Preference Alignment
2026. 3. 14.

Noise-robust and data-efficient preference optimization.
Introduction: The Alignment Dilemma
Aligning Large Language Models (LLMs) with human intent is a central problem in modern AI. While we have made massive strides using preference optimization, the underlying methods force researchers into a difficult compromise:
The Stagnation of Static References: Methods like Direct Preference Optimization (DPO) align models by regularizing updates against a fixed reference policy. However, as the active policy learns and drifts, this static reference becomes increasingly miscalibrated, leading to a distributional mismatch. Under noisy supervision, this mismatch can amplify spurious preference signals (such as rewarding a model simply for being verbose) rather than teaching robust semantic cues.
The Danger of Unconstrained Drift: Reference-free variants like SimPO fix the mismatch issue by defining rewards purely from the current policy's likelihood. However, removing the explicit stabilizer can cause the policy to over-optimize the implicit reward, resulting in unconstrained reward drift. This drift can actively harm the model's general reasoning capabilities and exacerbate its sensitivity to label noise.
These trade-offs highlight a missing ingredient in offline preference optimization: a stabilizer that adapts as the policy evolves.
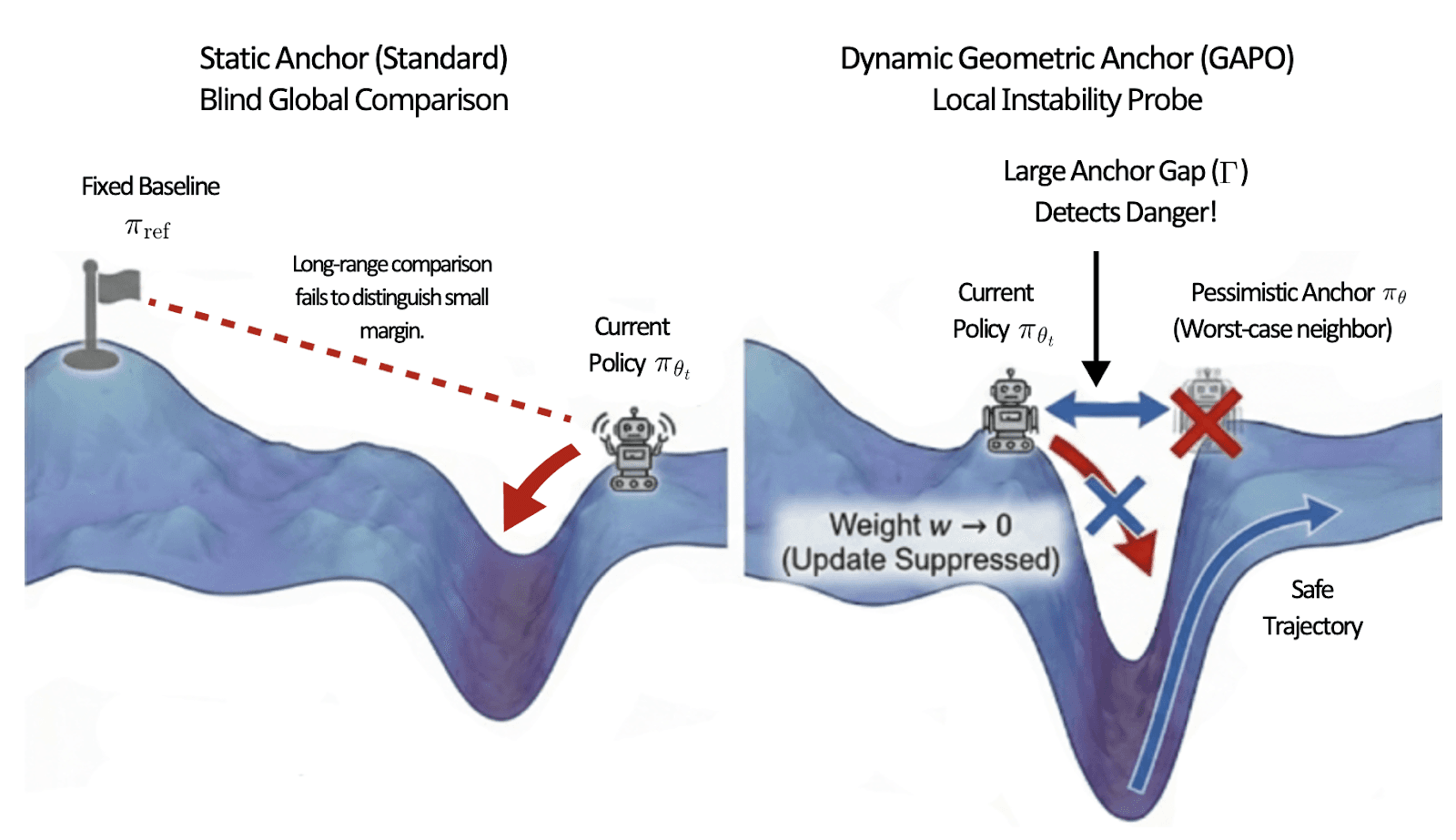
Figure 1. Comparison of Implicit Reward Landscapes and Objectives.
Method: The Geometric "Stress Test"
To resolve this tension, we introduce Geometric Anchor Preference Optimization (GAPO). GAPO replaces the outdated fixed reference with a dynamic, geometry-aware anchor.
Concretely, GAPO constructs a pessimistic local surrogate by applying an adversarial (worst-case) perturbation to the current policy within a small radius of the parameters. This acts as a geometric stress test for the model's preferences.
We then calculate the Anchor Gap: the discrepancy between the policy's implicit reward and the pessimistic anchor's implicit reward.
We use this gap to adaptively reweight the optimization objective:
High-Value Data (Stable): If a preference signal remains consistent even against the pessimistic anchor (a small Anchor Gap), it reflects robust semantics. GAPO assigns high weight to these instances, treating them as the core curriculum.
Low-Value Data (Brittle): If small distributional shifts cause the margin to collapse (a large Anchor Gap), the preference is locally brittle and likely tied to spurious memorization. GAPO effectively suppresses these instances by assigning them near-zero weight.
Results: Smarter, Safer, and More Robust Models
By penalizing geometric instability, GAPO acts as an implicit, automatic data curator. Our empirical evaluations across Mistral, Llama-3, and Gemma-2 model families demonstrate significant breakthroughs:
Superior Instruction Following: GAPO consistently matches or outperforms strong reference-based and reference-free baselines on standard benchmarks like AlpacaEval 2.0 and Arena-Hard.
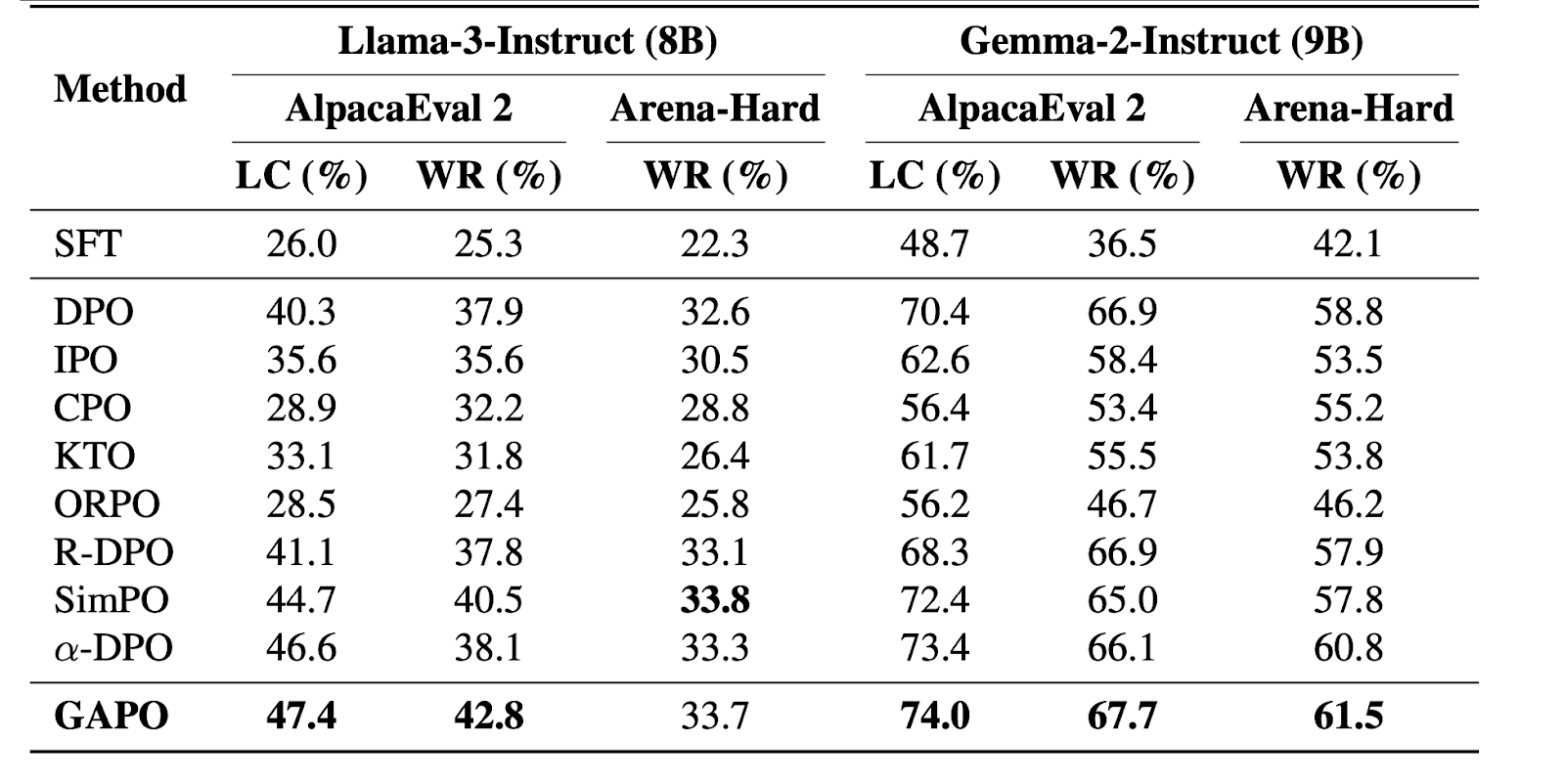
Table 1. Performance of the instruction-following task.
Low Alignment Tax: A common pitfall of alignment methods is the degradation of reasoning abilities.
GAPO improves alignment while largely preserving critical reasoning and mathematical performance on benchmarks like GSM8k and ARC-C.

Table 2. Reasoning vs Alignment Trade-off across models.
Extreme Noise Robustness: Real-world preference datasets are noisy.
When tested against both random label flips and structured noise (such as length-based biases), GAPO remained highly resilient. The instance-wise reweighting successfully suppresses the influence of brittle pairs without requiring explicit estimation of noise rates.
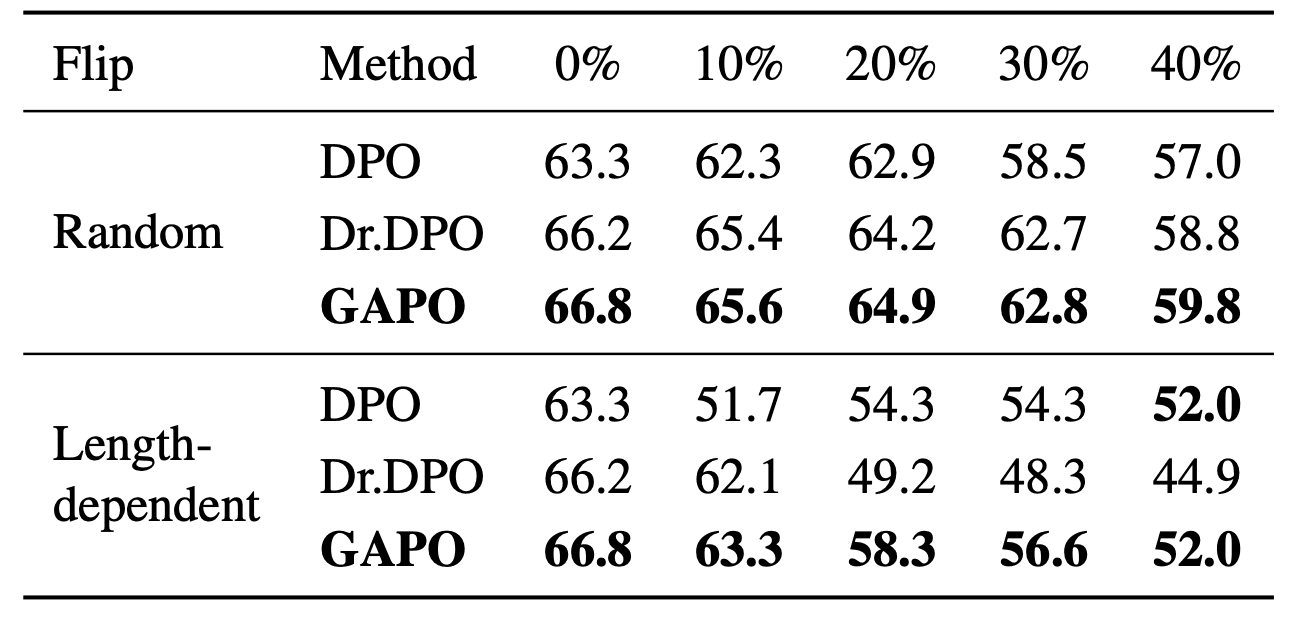
Table 3. Robustness against label noise.
Seeing is Believing: Preventing Hallucination
While quantitative metrics are essential, the true test of an alignment framework lies in the qualitative trustworthiness of its generated content. To understand how GAPO mitigates hallucinations compared to unconstrained baselines, let's look at a concrete case study on historical fact retrieval.
When presented with the prompt, "When was Canada colonized?", the difference in output quality is stark:

The Geometric Explanation: Why does this happen? From a geometric perspective, genuine factual knowledge typically resides in wider, more stable regions of the model's loss landscape. Hallucinations, on the other hand, are often "sharp" artifacts that arise from overfitting.
By actively penalizing geometric instability via the Anchor Gap, GAPO filters out these brittle hallucinations. It forces the model to rely on robust, generalized knowledge representations, proving that geometric anchoring fundamentally enhances the safety and trustworthiness of the generated content.
Conclusion: Redefining Reliability in Preference Optimization
As the demand for highly capable and aligned LLMs grows, the quality of human feedback and preference data remains a significant bottleneck. Geometric Anchor Preference Optimization (GAPO) introduces a geometry-aware framework that elegantly stabilizes learning without relying on an outdated, fixed reference model.
By constructing a pessimistic local anchor and using the resulting Anchor Gap as a signal to reweight updates, GAPO actively suppresses locally brittle supervision while emphasizing stable, high-quality preference signals. The empirical results are clear: GAPO improves instruction-following across various model families while crucially maintaining their core reasoning abilities and showing remarkable resilience to both random and structured noise.
Beyond the immediate optimization gains, this research offers a broader, profound insight for the AI engineering community: local geometric stability can serve as a highly practical proxy for the reliability of preference supervision. Rather than spending endless resources on trying to perfectly clean human-preference data, which is inherently noisy and imperfect, GAPO enables the learning algorithm itself to act as an implicit data curator.
Ultimately, frameworks like GAPO pave the way for safer, smarter, and more robust LLM deployments in real-world scenarios where data is messy, but alignment cannot be compromised.