Tech
Content Moderation
Multi-modal AI
Scalable AI
VideoUnderstanding
Efficiency at Scale: Bridging the Gap Between Fast Embeddings and Heavy LLMs
2026. 3. 7.

Decoupling retrieval from reasoning to handle millions of daily uploads while minimizing the LLM costs.
The Challenge: Multi-modal Complexity Meets Continuous Distribution Shift
Moderating video content at scale is fundamentally different from moderating text. A single YouTube video carries layered signals — a thumbnail image, spoken dialogue, background audio, and metadata like titles and tags. Each modality may tell a different story, and the 'true' meaning of a video is often found only at its intersection.
This complexity creates two compounding challenges that any production-grade content understanding system must address:
Volume and speed:
Platforms like YouTube process millions of uploads per day. Relying solely on a large language model (LLM) or a multi-modal LLM (MLLM) for every inference is not economically or technically feasible.
Continuous distribution shift:
The internet evolves constantly. New trends, slang, cultural contexts, and region-specific norms emerge constantly. A model trained on last year’s data may silently degrade when applied to today’s content, especially for nuanced categories such as hate speech.
PYLER's Content Moderation Pipeline was purpose-built to tackle both. In this post, we share the core architectural decisions behind our Video Understanding Engine and the reasoning behind them.
Two-Stage Pipeline: Fast Retrieval and Deep Reasoning
Rather than applying a single heavyweight model to every piece of content, PYLER's pipeline uses a two-stage architecture that separates fast, scalable retrieval from precise, reasoning-driven classification.
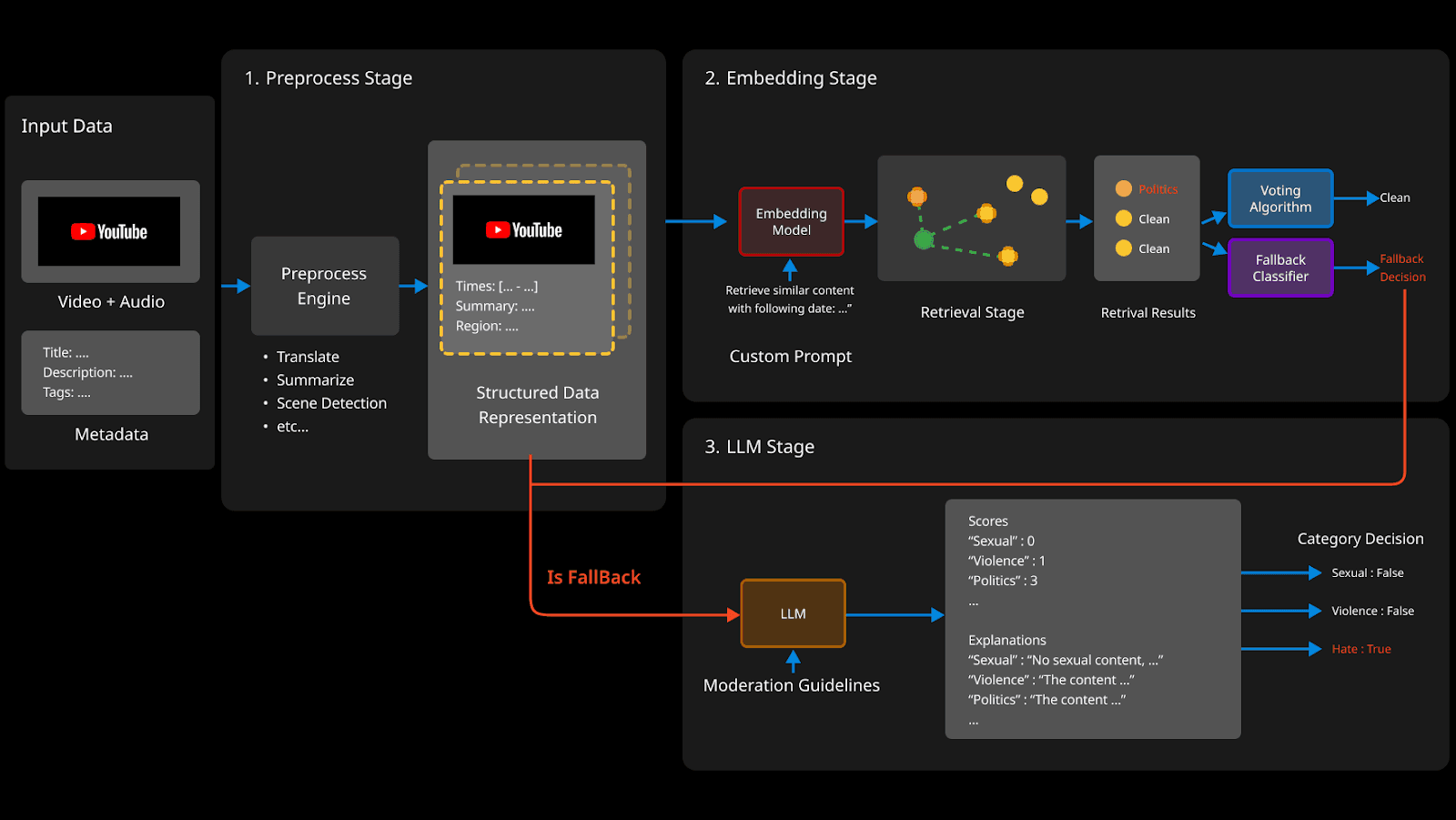
Figure 1. PYLER's end-to-end inference pipeline for multi-modal video content moderation.
The pipeline processes three input modalities simultaneously:
Video frames (keyframe thumbnails extracted from the video)
Audio signals (speech transcription + acoustic features)
Text metadata (title, description, tags, auto-generated captions)
These inputs flow through a Preprocess Stage (translate, scene detection, etc.), then branch into the Embedding Stage for the fast path, with an LLM Fallback Stage reserved for ambiguous cases.
Stage 1 — Multi-modal Embedding: Speed Without Sacrifice
The core insight of PYLER's architecture is that the vast majority of content — whether clearly safe or clearly violating — does not require LLM-level reasoning. Similar content tends to cluster together in embedding space, and a well-trained retrieval system can classify these cases instantly.
From Single-Modal to Truly Multi-modal
Conventional image-text encoders such as CLIP rely on dual-encoder architectures that align visual and textual representations in a shared space. While effective for cross-modal retrieval, they primarily optimize modality alignment rather than modeling rich interactions across multiple signals within a video.
PYLER adopts a different approach: a single instruction-tuned multi-modal embedding model that jointly encodes video, audio, and textual metadata into a unified embedding space. Instead of processing modalities independently, the model learns cross-modal correlations during representation learning, enabling more context-aware retrieval and detection.
A natural language instruction prompt dynamically steers the embedding model toward a specific detection category at inference time — without requiring architectural modification or task-specific fine-tuning.
This tri-modal framework integrates:
Video: keyframe-level visual representations extracted at scene boundaries
Audio: acoustic embeddings from speech and non-speech signals (music, crowd noise, tone)
Text: title, description, tags, ASR-generated transcripts, etc.
A custom instruction prompt enables category-aware retrieval by conditioning the embedding process on the desired detection objective.
"Retrieve the most relevant content for the given video, audio, and metadata ..."
Retrieval, Voting, and Fallback Detection
At inference time, the input is embedded and compared against a pre-built Hierarchical Embedding DB — a large corpus of labeled videos structured into multiple local embedding spaces.
Rather than searching a single global embedding space, PYLER’s pipeline performs Local-layer Retrieval, dynamically selecting the most relevant subspace for the query. These local layers can be defined along different axes, such as region (e.g., country or language), content category (e.g., product type or industry), or other domain-specific partitions, depending on the deployment setting.
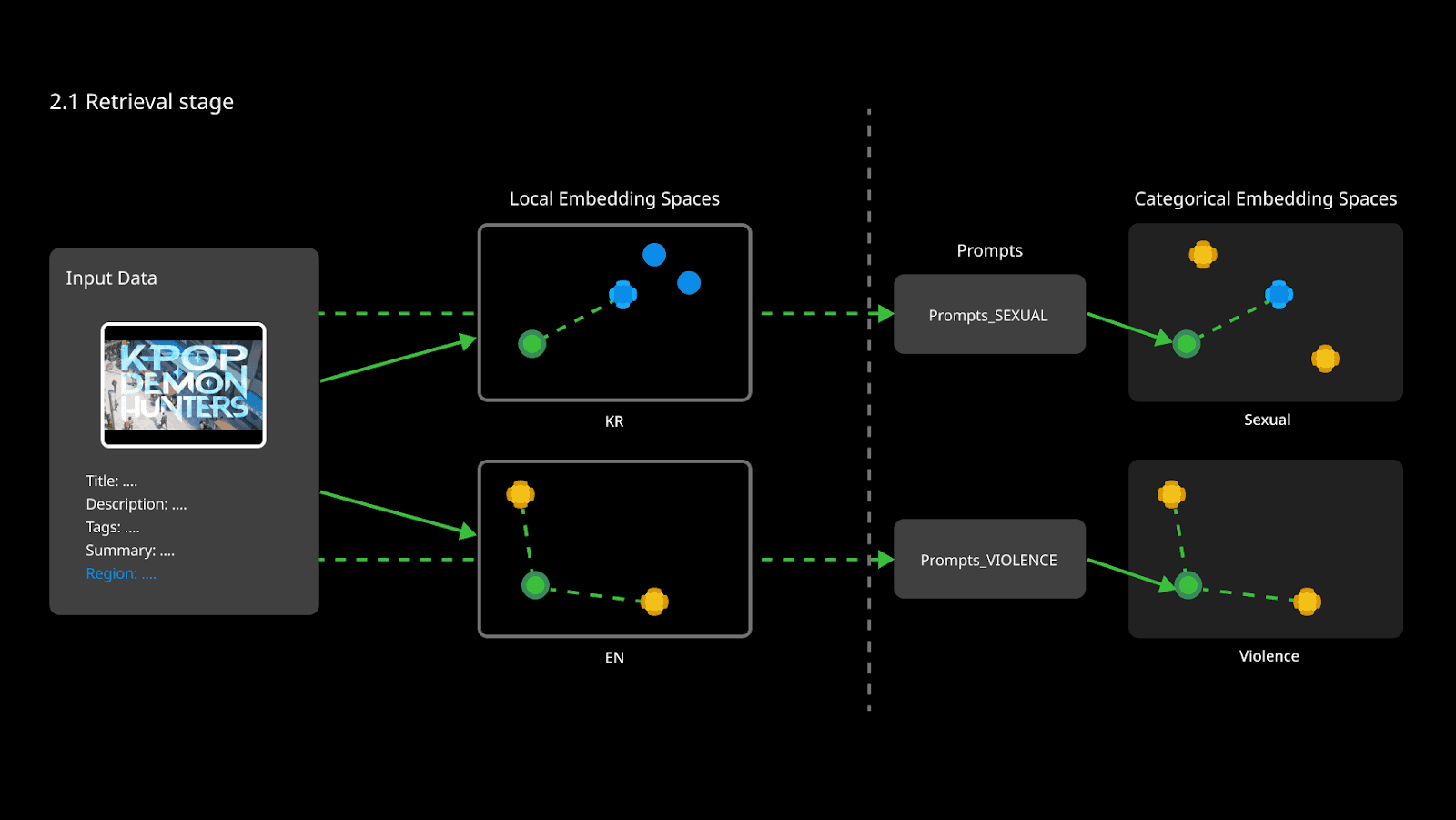
Figure 2. How PYLER Performs Hierarchical Retrieval: From Region-Aware Local Embeddings to Prompt-Guided Category Spaces.
This hierarchical organization reduces cross-domain interference and enables finer-grained, context-aware predictions tailored to the query’s distribution.
For each query, the top-K nearest neighbors are retrieved from the selected local space based on embedding distance. A distance-based weighted voting mechanism is then applied, where closer neighbors contribute more strongly to the final prediction.
When the neighborhood distribution is ambiguous or lacks a clear consensus, the system computes a hybrid confidence score — combining Label Entropy and Mahalanobis Distance — to identify difficult samples. These samples are categorized into two types and routed to the LLM Stage for further reasoning.
Uncertain samples: cases where retrieved neighbors carry mixed labels, indicating that the content sits on the boundary between categories. High label entropy signals this ambiguity.
Out-of-Distribution (OOD) samples: cases where the input sits far from any known cluster in the embedding space. A high Mahalanobis distance to the nearest labeled neighborhood indicates the content is genuinely novel — unseen patterns, emerging trends, or region-specific formats not yet well-represented in the Embedding DB.
Stage 2 — LLM Fallback: Precision When It Matters
For the subset of samples that the Embedding Stage cannot confidently classify, PYLER's pipeline invokes a large multi-modal language model. The LLM receives the full input - video frames, audio transcript, and metadata - alongside carefully engineered guidelines (rubrics) for each content category.
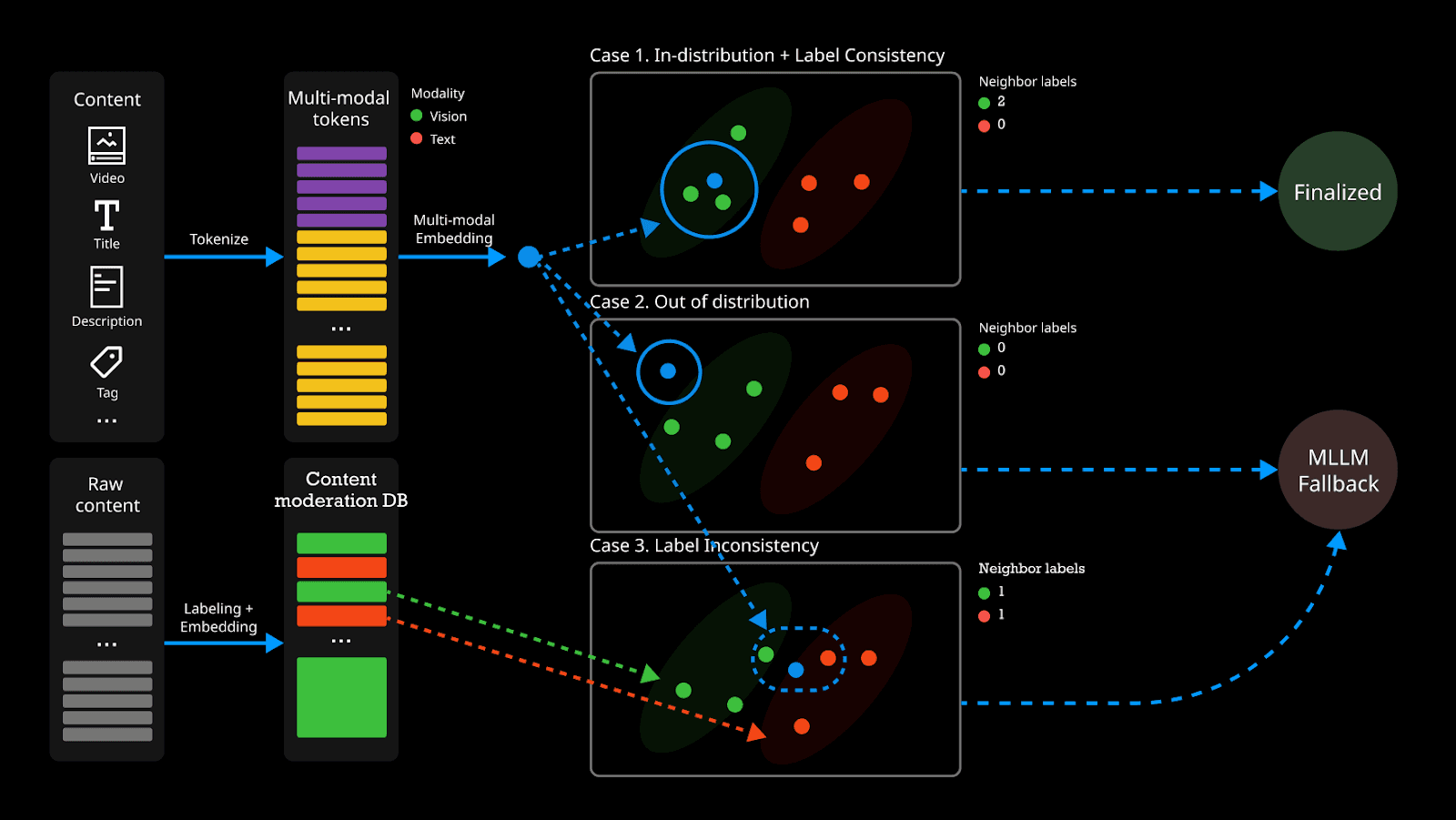
Figure 3. OOD and Label-Inconsistent Samples Are Routed to the LLM Fallback Stage.
The output is a structured JSON object with numeric scores and natural-language explanations for each category:
{ "scores": { "sexual": 0, "violence": 1, "hate": 3 }, "explanations": { "hate": "Targets a specific ethnic group..." } }
A final threshold rule converts scores into binary decisions. This interpretable output also feeds back into the human review queue, enabling continuous dataset improvement.
Multi-modal Embedding | LLM-based Analysis | |
Speed | ⚡ Very Fast (ms-level) | 🐢 Slower (s-level) |
Scalability | ✅ Highly scalable | ⚠️ Limited throughput |
Adaptability | ✅ DB-level update (no retraining) | ⚠️ Requires fine-tuning |
Accuracy (ambiguous) | ⚠️ May miss edge cases | ✅ High (nuanced reasoning) |
Cost | ✅ Low | ⚠️ High per inference |
Table 1. Embedding retrieval vs. LLM-based analysis — why both are necessary.
Staying Current: Human-in-the-Loop Feedback
No static model survives contact with a rapidly evolving internet. Content norms shift, new formats emerge, and regional context changes what is considered acceptable. PYLER's architecture treats this not as an edge case but as a first-class requirement.
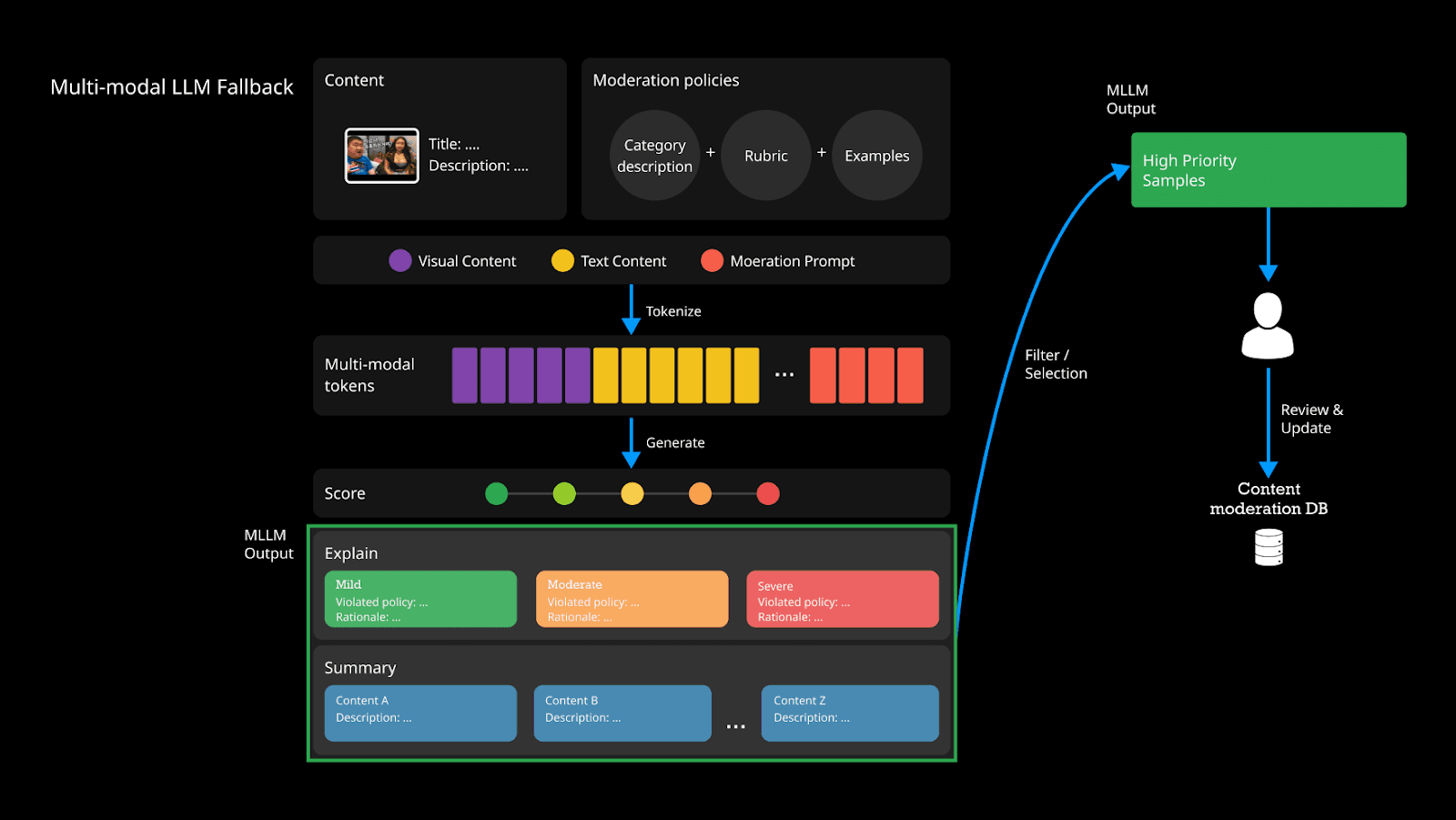
Figure 4. Human-in-the-Loop Feedback Updates the Embedding DB.
Instead of relying on infrequent retraining cycles, PYLER employs a continuous human-in-the-loop feedback mechanism centered on the Embedding DB.
Flagged samples from both the Voting Algorithm and LLM Stage are queued for human review.
Human labelers annotate new or ambiguous samples, with particular attention to emerging trends, regional slang, and novel content formats.
Newly labeled samples are embedded and added directly to the Embedding DB — no model retraining required. The retrieval system immediately begins using them for future predictions.
Systematic evaluation on held-out test sets tracks model drift and triggers targeted re-labeling campaigns when performance degrades on specific categories or regions.
This database-level adaptation — updating knowledge without retraining — is a defining architectural property of PYLER’s Content Moderation Pipeline.
Conclusion
Scaling content moderation across a global, multilingual, and rapidly evolving video platform cannot be solved by a single model alone. The challenge is not just accuracy — it is building a system that remains accurate over time, across regions, and against content that did not exist when the model was trained.
PYLER's Video Understanding Engine addresses this through a deliberate architectural separation of concerns. The multi-modal Embedding Stage handles the high-throughput majority of cases efficiently, while the LLM Stage brings deliberate, explainable reasoning to the cases that genuinely require it. Local-layer Retrieval ensures that predictions are grounded in contextually relevant reference data rather than a one-size-fits-all global space. And the human-in-the-loop feedback loop closes the gap between static training and a dynamic world — not through costly retraining cycles, but through continuous, database-level adaptation.
Together, these components form a system designed not only to perform effectively today, but to remain robust as the content landscape continues to evolve.